Xianzheng Ma (马宪政)
Greeting! I am currently a DPhil Student (10.2023- ) at Department of Engineering Science,
University of Oxford, supervised by Prof. Victor Prisacariu and Prof. Iro Laina.
I am a part of both the Visual Geometry
Group as well as Active Vision Group.
I am currently also working closely with Prof. João F. Henriques and Prof. Ingmar
Posner.
My research interests include 3D computer vision and robotics. Previously, I focused on
leveraging 3D Large Language Models to reason and understand the 3D world. More recently, I
have
shifted towards enabling robots to understand and interact with the physical world through
video and
3D modalities, with a current emphasis on utilizing world models to improve the
generalization capability of general-purpose robotic systems.
📢 I am actively seeking research internship opportunities
in robotics,
particularly in areas related to world models (3D or video). Feel free to
reach out!
For any suggestions or collaborations, please reach out to me at xianzheng@robots.ox.ac.uk.

News & Updates ( Last updated: 2026-03-13 )
- [2026-03-13] ✈️ I will be attending ICLR 2026 in Rio de Janeiro, Brazil to present our Real-3DQA paper. Feel free to reach out if you'd like to connect!
- [2026-03-13] 🎉 Our Beyond Single Object paper has been accepted to CVPR 2026 as a Finding!
- [2026-02-28] 🎉 Our See It, Say It, Sorted paper has been accepted to CVPR 2026!
- [2026-01-22] 🎉 Our Real-3DQA paper has been accepted to ICLR 2026!
- [2025-10-21] 📢 We have released the second version of our 3D-LLM survey, updated to include literature up to July 2025.
- [2025-10-03] 📢 New preprint: Inferring Dynamic Physical Properties from Video Foundation Models is now available on arXiv.
- [2025-09-26] 🏆 Selected as an Outstanding Reviewer (top 3%) at ICCV 2025!
- [2025-02-25] 🎉 Our robotics paper has been accepted to CVPR 2025!
- [2024-05-16] 📢 Check out our survey papers for 3D-related tasks empowered by LLMs and other foundataion models.
- [2023-12-16] We curated a Awesome-LLM-3D paper list for 3D-related tasks empowered by LLMs.
- [2023-12-15] Two papers are accepted in AAAI2024.
- [2023-10-02] Start a new journey as DPhil (PhD) at Visual Geometry Group and Active Vision Group in University of Oxford!
Selected Researches ( * Equal Contribution, † Correspondence Author, ‡ Equal Supervision )
Do 3D Large Language Models Really Understand 3D Spatial Relationships?
Xianzheng Ma* Tao Sun* Shuai Chen Yash Bhalgat Jindong Gu† Angel X Chang Iro Armeni Iro Laina Songyou Peng‡ Victor Adrian Prisacariu‡
International Conference on Learning Representations (ICLR) 2026
paper | project page | data | code | bibtex
We find that plain LLMs with zero 3D input can match full 3D-LLMs on existing benchmarks and propose a new benchmark and metric score for evaluating authentic 3D reasoning ability.
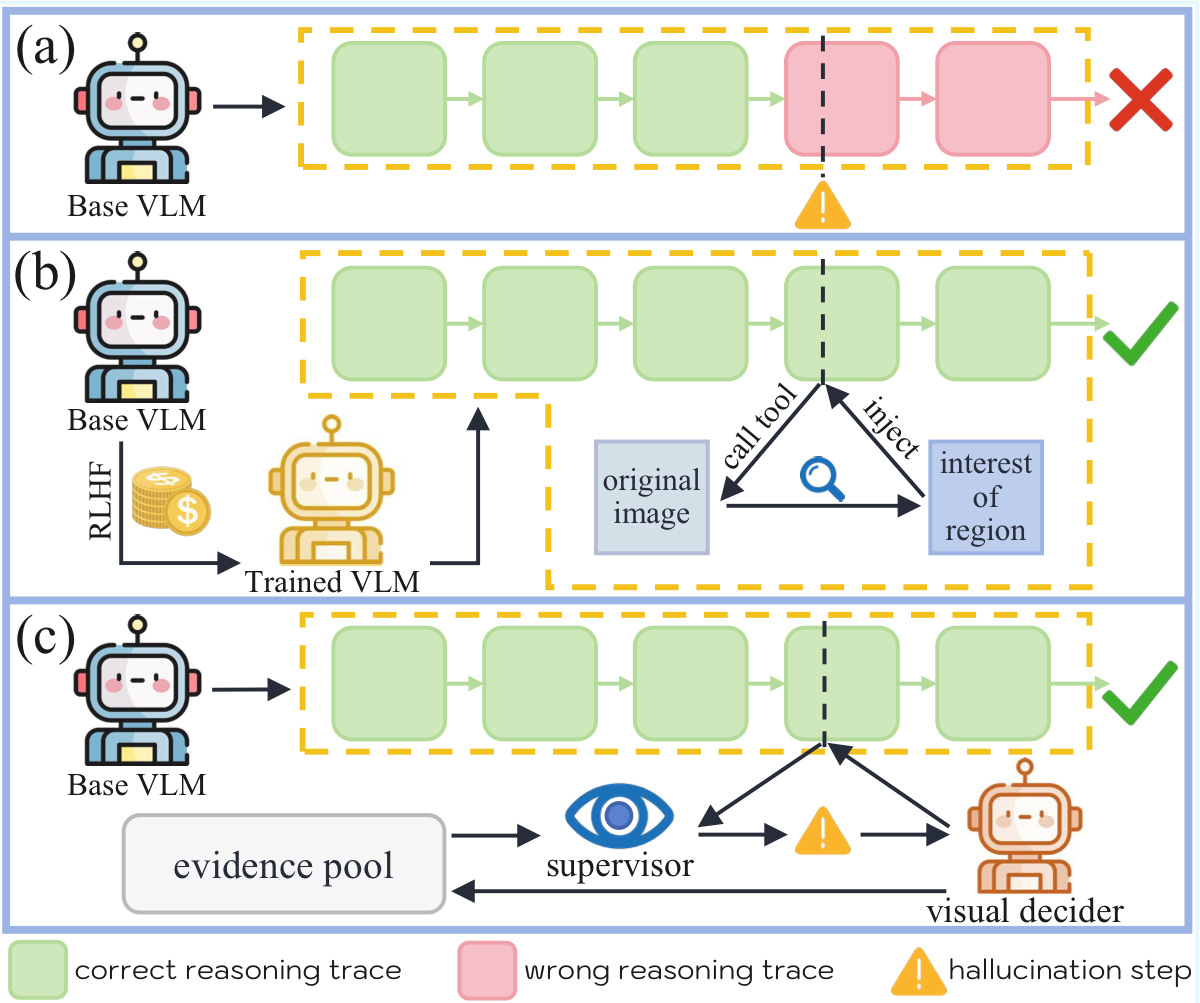
See It, Say It, Sorted: An Iterative Training-Free Framework for Visually-Grounded Multimodal Reasoning in LVLMs
Yongchang Zhang* Xianzheng Ma* Tianyi Liu Guangquan Zhou Yang Chen
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
We propose an iterative, training-free, plug-and-play framework that supervises each reasoning step with visual evidence, improving reasoning accuracy while effectively reducing hallucination rates across different model scales.
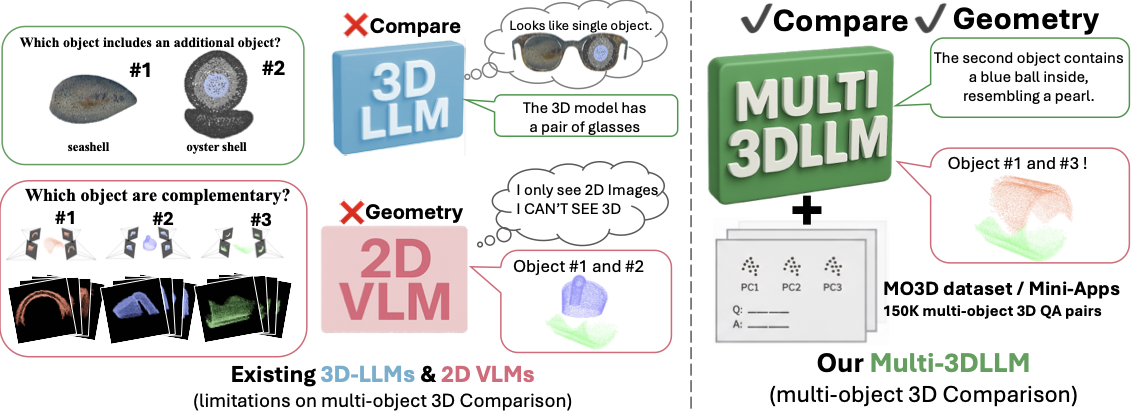
Beyond Single Object: Learning 3D Relations with Large Language Models
Kohsuke Ide Ryousuke Yamada Yue Qiu Xianzheng Ma Yoshihiro Fukuhara Hirokatsu Kataoka Yutaka Satoh
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026 (Finding)
We study learning 3D spatial relations between multiple objects using Large Language Models.

Inferring Dynamic Physical Properties from Video Foundation Models
Guanqi Zhan* Xianzheng Ma* Weidi Xie Andrew Zisserman
arXiv preprint 2025
We study the task of predicting dynamic physical properties (elasticity, viscosity, friction) from videos, via collecting a new dataset and contributing three methods using classical CV, video foundation models, and MLLMs.

Robotic Visual Instruction
Yanbang Li ZiYang Gong Haoyang Li Xiaoqi Huang Haolan Kang Guangpingbai Xianzheng Ma
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
paper | project page | code | bibtex
We propose a novel Human-Robot Interaction (HRI) paradigm designed to enable user-friendly, interpretable, and generalizable input methods for robot manipulation.
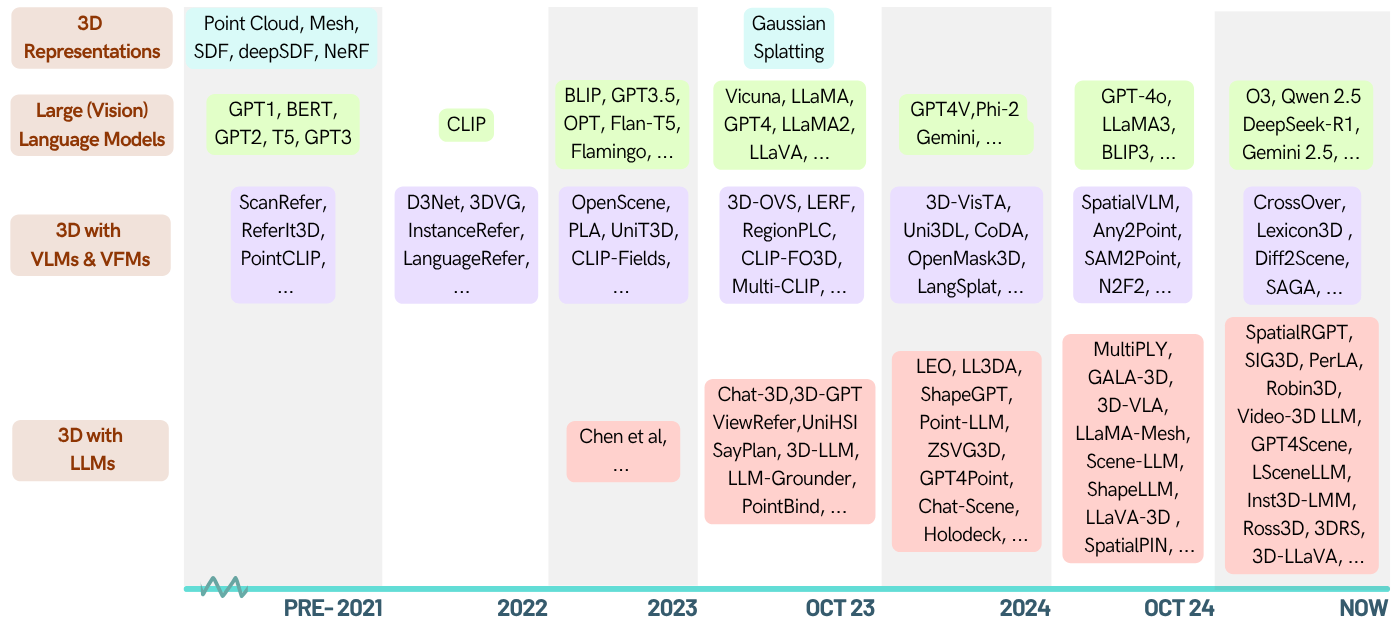
When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
Xianzheng Ma* Brandon Smart* Yash Bhalgat* Shuai Chen Xinghui Li Jian Ding Jindong Gu Dave Zhenyu Chen Songyou Peng Jia-Wang Bian Philip H Torr Marc Pollefeys Matthias Nießner Ian D Reid Angel X. Chang Iro Laina Victor Adrian Prisacariu
IJCV under review
paper | arxiv | project page | code | bibtex
We survey the papers of 3D understanding, generation, and embodied agent tasks empowered by LLMs and other foundataion models (CLIP, SAM)
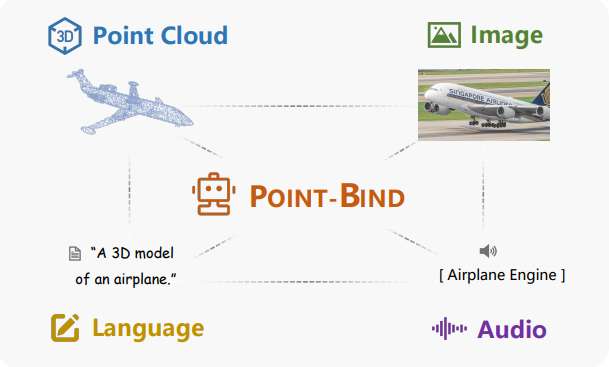
Point-Bind & Point-LLM: Aligning Point Cloud with Multi-modality for 3D Understanding, Generation, and Instruction Following
Ziyu Guo Renrui Zhang Xiangyang Zhu Yiwen Tang Xianzheng Ma Jiaming Han Kexin Chen Peng Gao Xianzhi Li Hongsheng Li Pheng-Ann Heng
paper | arxiv | project page | code | bibtex
We propose a 3D multi-modal model for general 3D learning, Point-Bind, and the first 3D large language model, Point-LLM
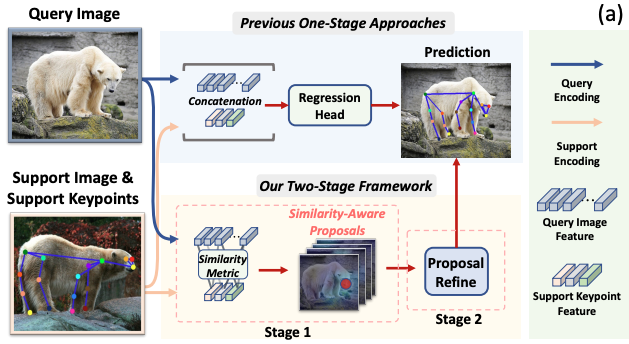
Matching Is Not Enough: A Two-Stage Framework for Category-Agnostic Pose Estimation
Min Shi Zihao Huang Xianzheng Ma Xiaowei Hu Zhiguo Cao
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023 Highlight
paper | arxiv | project page | code | bibtex
We propose a two-stage framework--CapeFormer for category-agnostic pose estimation.
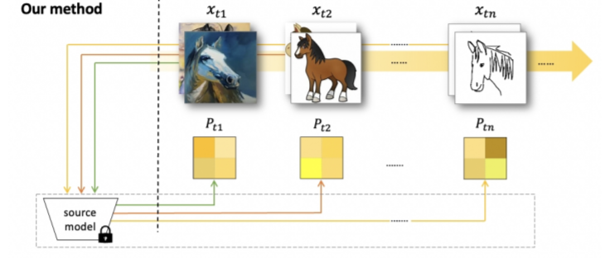
Decorate the Newcomers: Visual Domain Prompt for Continual Test Time Adaptation
Yulu Gan Xianzheng Ma Yan Bai Yihang Lou Renrui Zhang Nian Shi Lin Luo
AAAI Conference on Artificial Intelligence (AAAI) 2023 Outstanding Student Paper
paper | arxiv | project page | code | bibtex
We offer an alternative and new solution for continual test-time adapation by learning visual domain prompt.
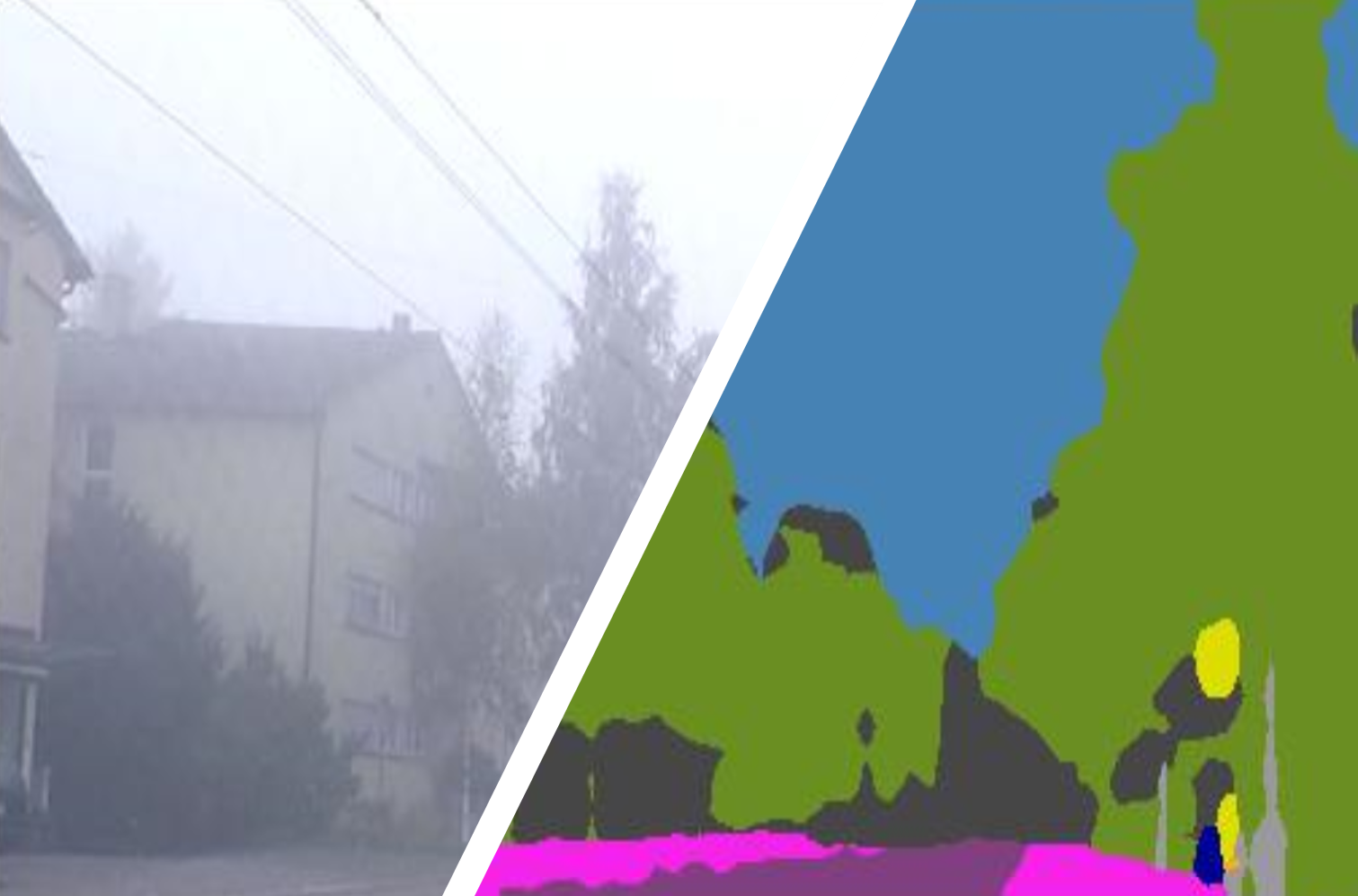
Both Style and Fog Matter: Cumulative Domain Adaptation for Semantic Foggy Scene Understanding
Xianzheng Ma Zhixiang Wang Yacheng Zhan Yinqiang Zheng Zheng Wang Dengxin Dai Chia-Wen Lin
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022 Oral
paper | arxiv | project page | code | bibtex
We alleviate the domain gap caused by mixed fog influence and style variation without labels.
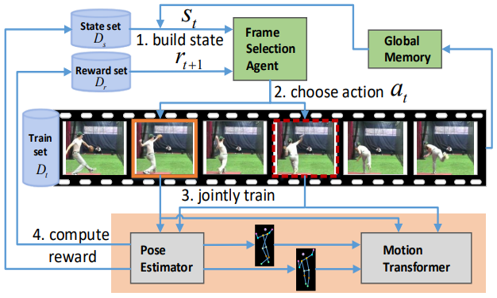
REMOTE: Reinforced Motion Transformation Network for Semi-supervised 2D Pose Estimation in Videos
Xianzheng Ma Hossein Rahmani Zhipeng Fan Bin Yang Jun Chen Jun Liu
AAAI Conference on Artificial Intelligence (AAAI) 2022
We offer an reinforcement learning based method to ultilize the temporal information in videos to train a robust pose estimator.
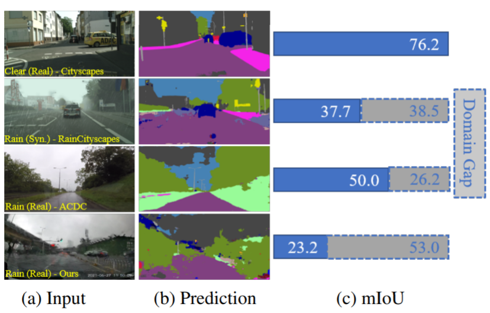
Rainy WCity: A Real Rainfall Dataset with Diverse Conditions for Semantic Driving Scene Understanding
Xian Zhong* Xianzheng Ma* Shidong Tu Kui Jiang Wenxin Huang Zheng Wang (* means equal contribution)
International Joint Conference on Artificial Intelligence (IJCAI) 2022
We propose a real-world rainy driving dataset for semantic segmentation and devise an unsupervised joint optimization framework based on contrastive learning.
All publications
Academic Services
- Conference Reviewer: CVPR'2022-2026, AAAI'2022-2026, ICLR'2023-2026, NeurIPS'2024-2025, ICCV'2025, ECCV'2024.
- Journal Reviewer: IJCV, TPAMI, TMM,
- Area Chair: IJCAI'2022 (China branch)
Misc.
- Sports: Swimming 🏊♂️, Badminton 🏸, Tennis 🎾
- Music: Recently started learning piano 🎹 — a great way to relax after research!
- Cooking: Steak enthusiast 🥩 — love pan-searing steaks at home. Favourite cut: ribeye.